It has been well documented that Google has been using a machine learning/natural language processing technology called “Rankbrain” (which is an extension of its Hummingbird algorithm) to help deliver more relevant search results since 2015.
Since the start of 2017/end of 2016 there has been a significant observable shift in the type of results returned by Google for certain types of keywords/conversational searches.
To give an example it’s first necessary to explain the difference in types of keywords:
Short Tail: Keyword (1-3 words) e.g. “Private Investigators”
National: Keyword + Country e.g. “Private Investigators UK”
Local: Keyword + Location e.g. “Private Investigators London”
Conversational: “How to tell if my partner is cheating”
Our Observations Post January 2017
Rankbrain has been deployed in the wild since mid 2016 and it appears to have been given a lot more weight since January of this year. This is immediately obvious when you look at the search results for short-tail, national & conversational:
Google appears to be attempting to understand the intent behind searches and is becoming A LOT BETTER at calculating the meaning behind a search
Local searches appear to be largely unaffected. For example, when a user searches for “Private Investigators London”, the intent behind the search is determined to be the user searching for a “Private Investigator in London.” Not exactly rocket science.
Short tail/national searches have changed dramatically. If a user searches for “private investigator” then what are they looking for? There is not enough information present to calculate the meaning of a search. Are they looking for a specific private investigator, a national company, a local company, news, career advice, costs, legal information?
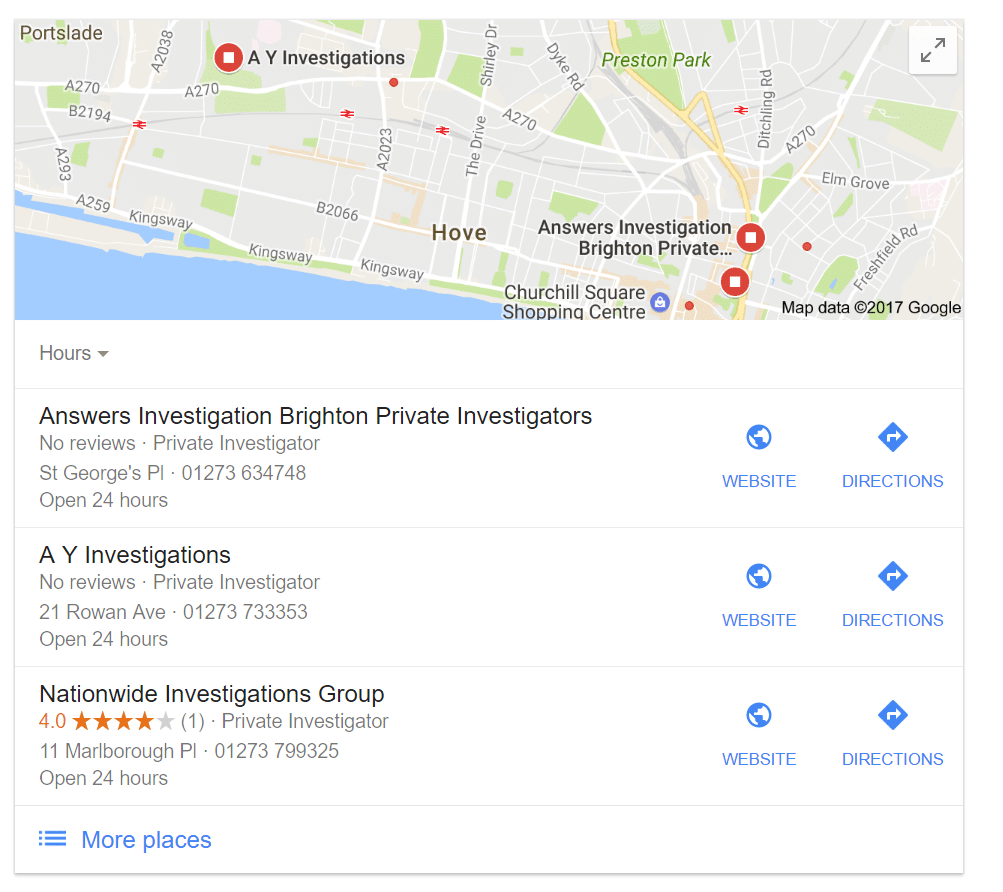
A working example “Private Investigator(s)” searched from Brighton, UK
Prior to January 2017, Google would return a list of the most relevant sites. What we are seeing now is VERY DIFFERENT. Where there is not sufficient information for Google to calculate the meaning behind a search e.g. a short tail/national keyword such as “private investigator(s)”, Google is presenting users with a diverse mixture of possible answers to a query.
People
Until a week ago, when we searched for “Private Investigators”, we were greeted with a list of famous/notable private investigators at the top of the page. Interestingly this has now dropped away (Rankbrain / machine learning being the prime suspect).
Local / Map
Whether you like it or not, Google knows where you are searching from.
How Much Does a Private Investigator Cost? (National Focused Websites)
Organic Local Sites
News (Nothing New Here)
Regulatory Information (General Information)
Hiring a Private Investigator (Guide)
Career Advice (Guide)
National Sites (not cost focused)
To summarise, this pattern is observable across multiple niches we work in, including real estate, addiction /rehab and more. Short tail and national searches are now yielding similar patterns.
Knowledge graph
Local pack if applicable
Costs
National sites
Local sites (organic)
News
Legal information
Career Information
In theory, this change yields better search results, returning a richer experience for users. The down side is that businesses which have enjoyed a page one position for short tail terms are now finding themselves at a significant disadvantage.
If you start to perform short tail searches a clear pattern is starting to emerge.
Why Is This Happening: Google Humming Bird Revisited
To understand what’s going on, the changes described above have been brewing in Google’s organic index since the beginning of 2013 starting with the implementation of the Hummingbird algorithm. – “Brett, semtuts.com”
Google stated at the time “Hummingbird” should allow it to better focus on the meaning behind words used in searches allowing Google to deliver results that go beyond just finding pages with matching words.
This was prompted by the evolution of search behaviour as the ratio of web-users transitioned from desktop computers to smart phones using speech to text PA’s e.g. SIRI. Rather than entering search commands using simple keywords, web users were transitioning to conversational search and its became necessary for Google to adapt.
The Calm Before The Storm
The release of Hummingbird at the time felt lacklustre and changes to the search index were not immediately observable. The roll out of Rankbrain in 2016 again felt underwhelming at the time however I would venture an opinion that what we are seeing is without a doubt one of the most significant changes/shakeups to the way Google’s search results are displayed since Penguin was released in 2012.
What is Rankbrain?
RankBrain is Google’s name for a machine-learning artificial intelligence system that’s used to help process its search results.
RankBrain is now one of the “hundreds” of signals that determines what results appear on a Google search results page. From out of nowhere, this new system has become what Google says is the third-most important factor for ranking webpages.
What is Machine Learning
Machine learning is a type of artificial intelligence (AI) that provides computers with the ability to learn without being explicitly programmed.
In the case of a search engine, Machine learning works by reviewing user behaviour to determine whether a page is a good fit for a keyword. The idea is the search engine monitors user behaviour and demotes pages with high bounce rates/low dwell times/low ctr rates.
To cite a memorable example Backlinko (a well known SEO site) posted a great article a few months ago provocatively titled “How to Get High Rankings In Search Engines.” At the time, the article was was ranking one page one for its primary keyword.
An unintended effect was the article also ranked for “how to get high.” When a Jessie Pinkman (Breaking Bad) wannabe clicked on Backlinko’s article, to their horror they were not greeted with a recipe from the “Anarchists Cookbook” describing how to produce LSD from banana skins, rather a detailed article about SEO: on-site optimisation. Users were not finding what they were looking for and left immediately (bounced).
After a few weeks, Google demoted the page for the keyword “how to get high.”
What is Natural Language Processing
Natural language processing (NLP) is a field of computer science, artificial intelligence, and computational linguistics concerned with the interactions between computers and human (natural) languages and, in particular, concerned with programming computers to process natural language rather than simple commands.
Put another way, our language is loaded with entities, key phrases in proximity one other (n-grams) which can be used to classify language by topic and calculate. If you want to see this in action a great tool is textrazor.com
Each word is analysed, entities / external data points in Wikidata are matched, semantic relationships parsed/reviewed and their meaning calculated. This limits the needs for structured data to drive the semantic web and also allows Google to calculate the meaning/intent behind a “search phrase.”
Try searching “how to tell if my partner is cheating” and look at the results. The search engine answers the questions producing a listing that includes direct answers with a mixture of language including “he/she/wife/husband/boyfriend/girlfriend/spouse” and substitutes cheating with infidelity. Now change “partner” to “husband” and look again.
Start Optimising for Topics, Not Just Keywords
Every update pushed by Google has set a pattern. According to SearchEngineWatch, Google is concentrating search results based on what users want and find most useful. Their goal has been to create the best possible experience in terms of the user’s experience.
The result has been an unprecedented push for authoritative content containing semantic relevance that delivers a positive user experience. We’re staring down the barrel of a new key focus, topical relevance.
Keywords—even keyword phrases—don’t hold a candle to topics in accomplishing this goal. Two excellent articles that cover the subject of topic research are found on Moz and SEMRush.
Key take aways from Moz and SEMRush articles and beyond
Start with KW Research then progress to topic research.
Welcome to the new era of SEO Writing. One of singular value decomposition and probabilistic models. Sounds horrendous.
I will be the first to admit that “determining context and relationships between terms / phrases and collections of entities” is not the easiest of concepts to get your head around. Furthermore finding worthwhile information on the subject matter is hampered by an overall lack of understanding within the SEO industry and the usual snake oil salesman latching onto LSI as a buzz phrase/attempting to sell the uninformed masses so-called LSI keyword tools that don’t work as advertised.
Topic Classification
Topic classification works by algorithmically classifying the language within text/a document into categories/taxonomies.
For those of us producing content with the intent of attracting search traffic, the idea naturally follows to seed the text we create with related language to give it context which is a something we all do naturally to a certain extent. It allows people to understand and search engines to calculate the topic of a document/phrase/word. For example, if I use the word “Apple,” it has multiple meanings.
Apple = Fruit
Apple = Apple Computers
Apple = Apple Corp / Apple Records
The way both human beings understand the meaning behind the word and now search engines calculate context through natural language processing is by looking at language used in proximity to a specific term..
Fruit = Crunchy, juicy, delicious, healthy
AppleComputers = Steve Jobs, Ipod, Iphone, Ipad
Apple Records = Beatles, Sgt Pepper, John Lennon
In the context of this job I would have provided you with a list of words and simply asked you to weave them into your writing where possible.
TIP’s for Finding LSI Related Language
Start with keyword research. Adwords is a great starting point. Since its acquisition of semantic labs in 2003, Google’s Adwords keyword planner tool will suggest related terms as well as similar keywords. Just apply a negative filter for the primary keyword and export related terms.
Next analyse competitor’s websites that are already ranking. Use text analysis tools e.g. ranks.nl and text razor to extra topics and entities and add these to your website’s text. Do this with every service / product you offer.
The final piece of the puzzle is reviewing how the semantic web works. Semantic associations between entities are powered by wikidata. Pull up the Wikipedia page for a core topic and run the text through Text Razor and build a list of entities and work these into your copy as well.
e.g. Furniture -> Wood -> Type of Wood -> Type of Tree
e.g. Funeral Director -> Funerals -> Death – > Grief -> Coffins -> Cremation
Write With Authority and Answer Questions Within Your Text
Look at working factual headings and questions into the text using H2 tags and answer questions e.g.
What is alcohol dependence?
What causes alcohol dependence?
Signs and symptoms of alcohol dependence
How to reduce your risk of becoming alcohol dependent
Effects of alcohol dependence on the body
Mental health problems
Alcohol withdrawal symptoms
How to get treatment
SEMRush KW Magic, Moz, KWFinder and Answerthepublic.com can quickly help you find questions that users are asking the search engines.
How do I Apply This to My Site?
Work micro FAQ’s into pages to build context and create pages/posts dedicated to comprehensive articles and link between pages using questions, statements and prepositions as the anchor text.
Cost/Career/Legal Information?
If a short tail search is showing a clear pattern (see above), then create pages/content that provide similar answers. SEO is a game of match and exceed, so make your answers more comprehensive, longer and more authoritative.
Internalise Entities Within Your Site to Build Context
Start creating pages on your site focusing on entities and mark them up with structured data. If you were running a locksmiths website (example 1/example 2) build collection pages that focus on different types of locks, lock brands and concepts e.g. security. A great plugin to aid with this is Wordlift.io Their website is a little ambiguous but trust me, its going to be one of the must have plugins/services moving forward and there’s nothing on the market that comes close.
Using Schema to Build Context
Start marking up each reference to an entity with structured data / schema. The trick is to reference entities within your site using semantic linking from general pages to entity collection pages.
e.g. Home Page (references Chubb Locks). -> Link to /chubb/ page within the locksmiths website.
Next link from the entity page to external data points e.g. Wikipedia, Wikidata, official website.
This will help build context and is set to become increasingly important over the coming weeks and months. The same strategy can be applied to link building and local SEO.
Rankbrain Ranking In A Nutshell
Take your website
LSI enhance the existing content
Add basic structured data (local business, website, site elements)
Google Local SEO (if applicable)
Topic research around KW research / LSI variants
Start NLP adding questions and answers into the site, on regular pages and setup longer pages to explore answers in depth
CCC Content Strategy
CRUMBS – small snippets of information (short blog posts)
COOKIES – larger pages focusing on a specific topic
COLLECTIONS – Massive pages focusing on a single entity.
STRUCTURE – HTML Should be structured with H2’s, tables, lists
QUESTIONS/PREPOSITIONS – Headings should contain questions with answers immediately below
Use tools e.g. Textrazor and Alchemy api to extract entites / context and addition LSI options
Work them into the text if missing
Create collection pages for entities
Link internally to question + answer pages and collection pages
Link from collection pages with NLP anchor text to questions and answer pages
start adding structured data from your main pages and questions / answer pages to your collection pages
Reference external entities e.g. Wikipedia/DBPedia and authority sites from your collection pages with links and structured data